February 18, 2026
AI evaluations: Ensuring quality in Recurly's AI platform
TABLE OF CONTENTS
TOPICS
RELATED POSTS

At Recurly, we are dedicated to thoroughly integrating AI across our platform. We have a strong history of applying machine learning in our products and services. As LLMs and AI agents have rapidly advanced, we’ve established a robust foundation to deliver AI benefits while actively mitigating potential risks. Central to this foundation is our AI evaluation system.
The core of our AI initiative is Recurly Compass, an integrated AI system powering our platform and products. While it may appear as a simple chatbot, it is built upon a complex, hierarchical network of agents, MCP servers, and tools that are continuously expanding in scope and capability. As we develop new agents and intelligent features, ensuring their consistent performance is paramount.
How we run evaluations in our AI system
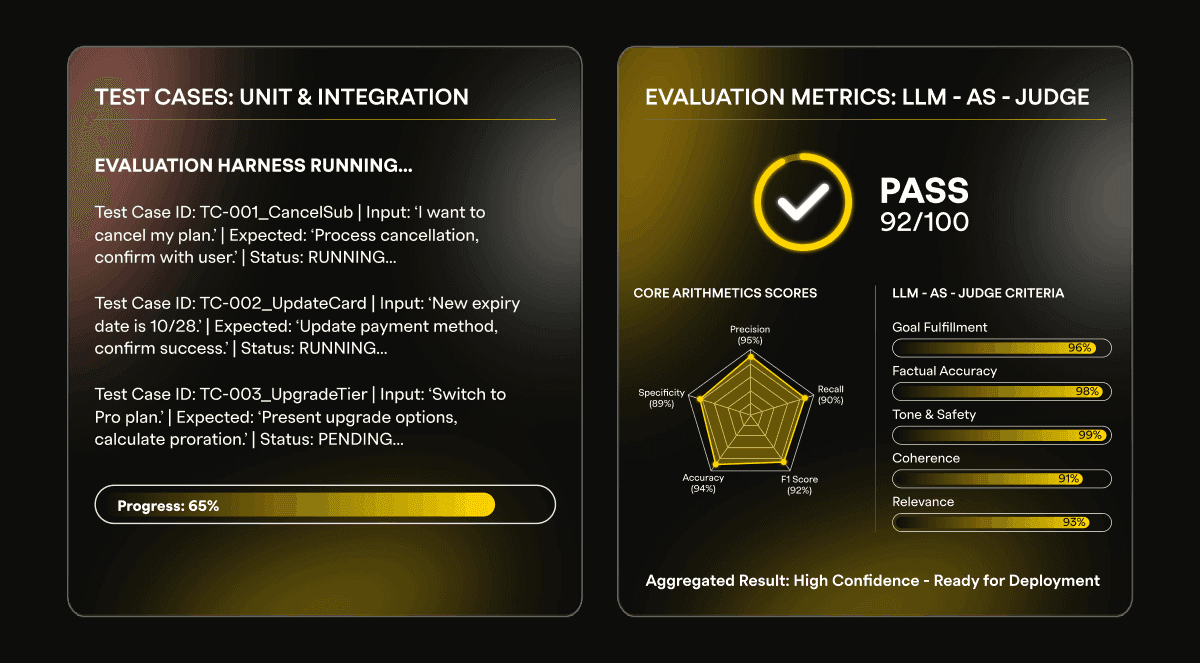
To provide this assurance, the Data Science team developed an evaluations harness utilizing open-source frameworks. This allows us to run evaluation test cases against our agents and accurately measure their performance.
An AI evaluation, at its most basic, functions like a unit or integration test for an AI application. It consists of two primary components:
Test case: This includes a sample user input and the expected response from the AI assistant
Metric: This defines how the actual response will be graded against the expectation
Our initial strategy involved manually defining a suite of test cases and appropriate metrics for each agent as it was built. This was a collaborative effort between agent developers, who understood the critical functionality, and data scientists, who selected or defined the necessary metrics. Our metrics include off-the-shelf and custom metrics, such as:
LLM-as-judge metrics: Where a specifically prompted LLM is used to evaluate the agent’s performance
Arithmetic scores: This includes precision and recall, applied to specific facts and artifacts in the agent's response
LLM-as-judge metrics can be built from scratch with suitable prompts or they can be accessed in various evaluation libraries. At Recruly, we have been using DeepEval, which makes it easy to use the G-Eval metrics. There are many situations, however, where we want to measure very specific situations and these are where we built simple metrics. Some of our agents return source URLs for their answers or URLS for navigation within the Recurly UI. We don’t need an LLM to judge these, we can do direct matching of the URLS (or other artifacts). DeepEval also makes it easy to run all of the test cases and metrics multiple times so we can average your metrics over multiple iterations.
Moving on to “Phase 2”
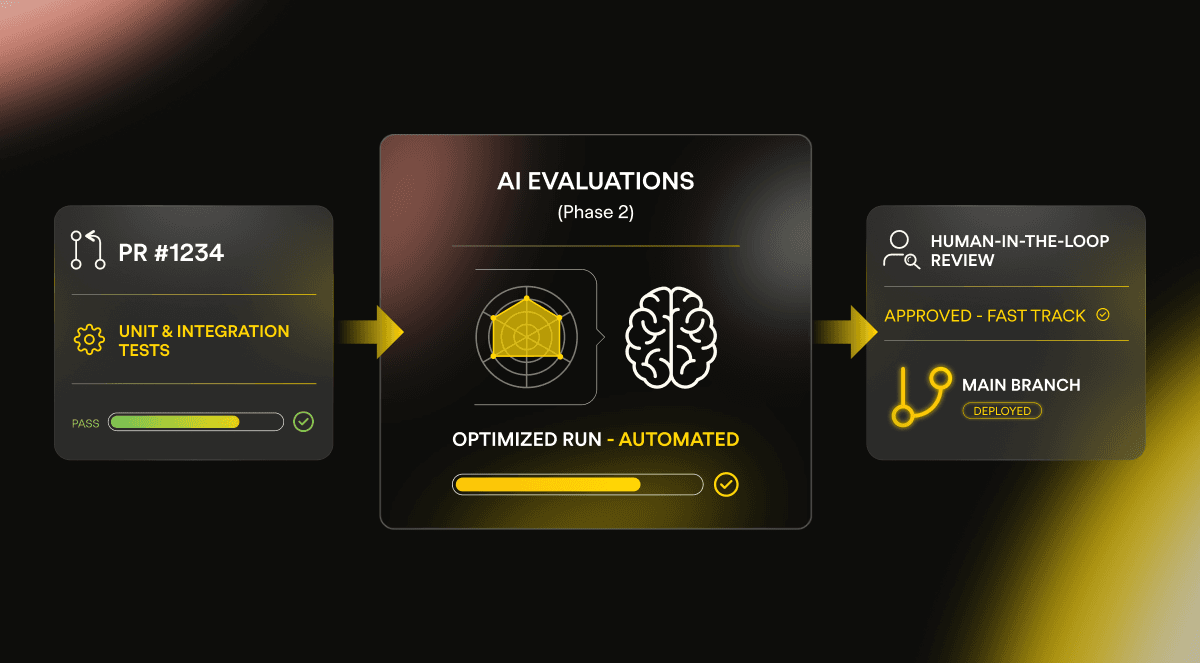
These were our “Phase 1” evaluations, functioning as unit and integration tests to detect any performance regressions. We are now in “Phase 2” which entails automating and streamlining the process of building and running evaluations and introducing human-labelling to actual AI conversations to help us improve performance, not just catch regressions.
To accomplish the automation and streamlining, we have been working on a more complete implementation model for the evals. As the number of agents has grown, we have encountered increasing complexity in maintaining test cases and metrics and ensuring adequate evaluation coverage. Running all evaluations on every Pull Request (PR) now takes quite a bit longer than before and is negatively impacting our PR review and merge workflow.
We are currently solidifying our evals process by explicitly defining how we build test cases, how we select and apply metrics, and how we can efficiently run the evals. Our approach includes three core steps:
Optimizing metrics to efficiently maximize coverage
Synthesizing high-quality test cases that reflect the agents' business intent and technical basis
Partitioning evaluations into “tiers” with different triggers and cadences
This approach was inspired by the Goal-Plan-Action (GPA) model, which defines three evaluation scopes. We adapted this model to suit our existing agents, metrics, and to incorporate low-level performance evaluations that fall outside the canonical GPA framework.To achieve this, we are addressing the following areas:
Metrics gap analysis
Metrics tier classification (e.g. simple tests of tool calls vs multi-turn, LLM-as-judge evals like goal fulfillment)
Determination of proper triggers and cadences for the evaluation tiers: qa and staging PRs, PR to master, and scheduled
The metrics gap analysis has been a particularly insightful exercise as it forces us to clarify the purpose and scope of each metric and understand how they fit together to accomplish our goals. We find that understanding metrics in this manner is critical to thinking in terms of tiers and triggers to maintain high confidence and low friction.

Our expected outcomes for AI evaluations
The real prize in our Phase 2 of evaluations is the human-labelling. The goal here is to reach beyond what we can do with fixed test cases and get direct ratings of actual conversations from our internal experts. Our human-labelling efforts began with simple queries of actual conversations from the data warehouse and sending an appropriate selection to subject matter experts (SMEs) in a simple spreadsheet form.
We are now exploring labeling tools with better UX that can lighten the cognitive load on the SMEs to give good quality ratings. AS we continue down this path, the SME ratings will be used to fine-tune and improve our agents.
AI evaluations are a critical and rapidly-evolving space that is often overlooked amid the hype of Agentic Workflows.
At Recurly, we are committed to being at the cutting edge of technology to improve our customers’ success and that includes a commitment to building and verifying the highest quality AI tools. AI evaluations are integral to building the subscription management platform of the future. Want to learn more about Recurly Compass? Check out our page here.
Want to learn more about Recurly?
